Some time ago, it occurred to me that the way we’re currently tackling the pp system problem is riddled with bias. People have to communicate their ideals for what makes the most fair pp system in terms of “buff this” and “nerf this” in a small sample size which doesn’t account for quite a bit of the complexity of the problem at hand. The process of reaching a widespread consensus through hard coded algorithms is unnecessarily tedious and takes a very long time. So, I figured the solution would be implementing neural networks.
*Note: I don’t mean any of this to come across as condescending, I just want everything to be clear to as many people as possible.
What exactly is a neural network?
For those who don’t know, a neural network is a computer programming process which uses data to build some sort of algorithm for a complex process not easily coded, yielding a similar result. For example: you give a program the pixel data for several images of animals. These pictures are labeled with what animal is represented, but this information isn’t shared with the computer. The computer will use the pixel data to come to some conclusion about what animals are represented. It goes through every image provided and eventually, its results are compared to the actual answers. This happens several times, all with different methods of coming to a conclusion. The program will then try to use similar processes to the most successful of the processes in the next “generation” where several different processes go through the set of images again. This is repeated several times and eventually yields a scarily accurate classification of what animals are in which picture.
How could this be applied to pp?
My idea goes through several steps:
Finding “Score Rankers”
Obtaining a large amount of data from a sample of scores
Ranking scores in terms of “impressiveness”
Translating the list into pp
Running the neural network
Assessing the results
Finding “Score Rankers”
The first step for achieving the “correct” answer which will be the template of our neural network is to find people that are very familiar with the game. People who have shown that they have a diverse skillset, usually the type to argue on Twitter kinda deal. So my first instinct here would be high ranked tournament players but there could be several ways to find the people we’re looking for. Whatever the group ends up being, these people would go through a process similar to BN applications to get promoted as an “SR” (I know this already stands for star rating, but let’s just ignore that for the purposes of this hypothetical.)
Obtaining Data
Next, we need to find a sample of scores to be assessed. We can take tons of different things from the plays ranging from difficulty over time functions, combo over time functions, accuracy over time, SV over time, Spacing over time, rhythm density over time, etc. All of these, of course, could just have an average (1/[time interval] * integral from 0 to [time interval] f(t) dt) but I think getting specific functions will aid in getting ideal precision, however that is a compromise that could be made if that ends up causing too much strain on the servers.
An issue arises though over which scores to be sampled. If a random sample is taken, the sample wouldn’t be representative of more impressive scores since there’s a substantially lower density of these (Which I would argue are much more important than the average score.) If only competitive scores are sampled, then most scores won’t be accounted for. There has to be a happy medium in the distribution of sampling. A sort of “sampling bias” heuristic would have to be made.
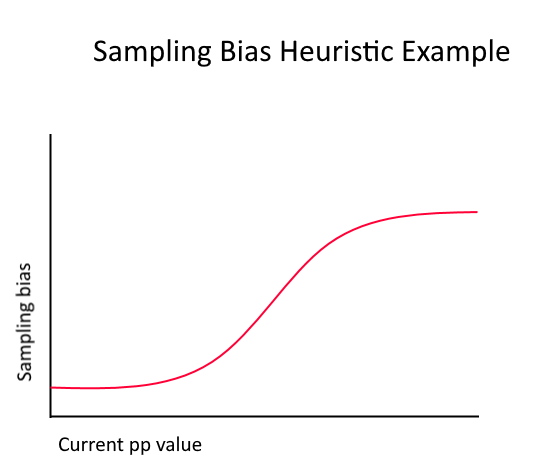
Ranking Scores’ “impressiveness”
We hand over a replay of the sampled plays to the SRs and they simply rank them based on their impressiveness. Why impressiveness? This is an attempt to remove the current fixed mindset over “this should reward more pp” vs “this is overweighted” etc. For example, we’re used to tech map plays being underweighted for their actual value in the pp system, but we do usually agree they’re impressive, so this is the most ideal metric in my opinion. The maps don’t have to be the same given to every SR as long as there’s enough input per map.
Translating the list into pp
Now we make this list mean something. This isn’t very straight forward though. As mentioned before, there’s a disproportionate amount of high pp plays compared to low ones. We can’t just say “pp is proportional to the average ranking on the list of a score” or else the difference between the two Easy diff scores could be the same as that between two 8* scores. The solution is to find the pp density graph in order to try to emulate the distribution of pp the current system has. Think about it like this: you rank every single score currently set on osu! based on pp value and have to guess what the values are. You would probably put #1 around 1200, a few 1100, a few more between 1k and 1100, and more and more until you got to a huge string of 0pp plays. This is what getting the density graph lets us do with accuracy. However, you also need to account for the sampling bias we had when picking these scores. So the process would be to sample a large amount of scores with the sampling bias heuristic used before and get the pp density graph which would be used to assign the pp value of scores on the list.
Running the neural network
Everything is set in place and now all that needs to be done is for all the data collected to be put on a computer program. Personally, I’ve only made a neural network in the past using tensorflow in Python, but I’m sure there’s somebody more qualified who could give a better recommendation for how this would be done. When the neural network gets pretty accurate, we’re free to start testing the results on a larger scale.
Assessing the results
The assessment process we have now would work just fine. Set up a github where people can submit their profiles/scores and have a global leaderboard. People will inevitably do the critiquing on Twitter soon after.
Conclusion
I kinda just threw this together really briefly in about an hour, so it’s bound to be flawed, but that’s my general take for what could be a pretty neat approach for this unique problem we got. Like I mentioned before, the process we’re going through right now just seems unnecessarily slow and biased, so I really do hope some alternative is found even if it’s not this. Shoutouts to everybody who’s made an effort to improve the system, it’s a huge motivator for people to keep improving. Let me know if there’s any changes that could be made to make this easier to understand/ improvements to the method I proposed.
*Note: I don’t mean any of this to come across as condescending, I just want everything to be clear to as many people as possible.
What exactly is a neural network?
For those who don’t know, a neural network is a computer programming process which uses data to build some sort of algorithm for a complex process not easily coded, yielding a similar result. For example: you give a program the pixel data for several images of animals. These pictures are labeled with what animal is represented, but this information isn’t shared with the computer. The computer will use the pixel data to come to some conclusion about what animals are represented. It goes through every image provided and eventually, its results are compared to the actual answers. This happens several times, all with different methods of coming to a conclusion. The program will then try to use similar processes to the most successful of the processes in the next “generation” where several different processes go through the set of images again. This is repeated several times and eventually yields a scarily accurate classification of what animals are in which picture.
How could this be applied to pp?
My idea goes through several steps:
Finding “Score Rankers”
Obtaining a large amount of data from a sample of scores
Ranking scores in terms of “impressiveness”
Translating the list into pp
Running the neural network
Assessing the results
Finding “Score Rankers”
The first step for achieving the “correct” answer which will be the template of our neural network is to find people that are very familiar with the game. People who have shown that they have a diverse skillset, usually the type to argue on Twitter kinda deal. So my first instinct here would be high ranked tournament players but there could be several ways to find the people we’re looking for. Whatever the group ends up being, these people would go through a process similar to BN applications to get promoted as an “SR” (I know this already stands for star rating, but let’s just ignore that for the purposes of this hypothetical.)
Obtaining Data
Next, we need to find a sample of scores to be assessed. We can take tons of different things from the plays ranging from difficulty over time functions, combo over time functions, accuracy over time, SV over time, Spacing over time, rhythm density over time, etc. All of these, of course, could just have an average (1/[time interval] * integral from 0 to [time interval] f(t) dt) but I think getting specific functions will aid in getting ideal precision, however that is a compromise that could be made if that ends up causing too much strain on the servers.
An issue arises though over which scores to be sampled. If a random sample is taken, the sample wouldn’t be representative of more impressive scores since there’s a substantially lower density of these (Which I would argue are much more important than the average score.) If only competitive scores are sampled, then most scores won’t be accounted for. There has to be a happy medium in the distribution of sampling. A sort of “sampling bias” heuristic would have to be made.
Ranking Scores’ “impressiveness”
We hand over a replay of the sampled plays to the SRs and they simply rank them based on their impressiveness. Why impressiveness? This is an attempt to remove the current fixed mindset over “this should reward more pp” vs “this is overweighted” etc. For example, we’re used to tech map plays being underweighted for their actual value in the pp system, but we do usually agree they’re impressive, so this is the most ideal metric in my opinion. The maps don’t have to be the same given to every SR as long as there’s enough input per map.
Translating the list into pp
Now we make this list mean something. This isn’t very straight forward though. As mentioned before, there’s a disproportionate amount of high pp plays compared to low ones. We can’t just say “pp is proportional to the average ranking on the list of a score” or else the difference between the two Easy diff scores could be the same as that between two 8* scores. The solution is to find the pp density graph in order to try to emulate the distribution of pp the current system has. Think about it like this: you rank every single score currently set on osu! based on pp value and have to guess what the values are. You would probably put #1 around 1200, a few 1100, a few more between 1k and 1100, and more and more until you got to a huge string of 0pp plays. This is what getting the density graph lets us do with accuracy. However, you also need to account for the sampling bias we had when picking these scores. So the process would be to sample a large amount of scores with the sampling bias heuristic used before and get the pp density graph which would be used to assign the pp value of scores on the list.
Running the neural network
Everything is set in place and now all that needs to be done is for all the data collected to be put on a computer program. Personally, I’ve only made a neural network in the past using tensorflow in Python, but I’m sure there’s somebody more qualified who could give a better recommendation for how this would be done. When the neural network gets pretty accurate, we’re free to start testing the results on a larger scale.
Assessing the results
The assessment process we have now would work just fine. Set up a github where people can submit their profiles/scores and have a global leaderboard. People will inevitably do the critiquing on Twitter soon after.
Conclusion
I kinda just threw this together really briefly in about an hour, so it’s bound to be flawed, but that’s my general take for what could be a pretty neat approach for this unique problem we got. Like I mentioned before, the process we’re going through right now just seems unnecessarily slow and biased, so I really do hope some alternative is found even if it’s not this. Shoutouts to everybody who’s made an effort to improve the system, it’s a huge motivator for people to keep improving. Let me know if there’s any changes that could be made to make this easier to understand/ improvements to the method I proposed.